

MS Project Cortex - Knowledge Management & AI

Microsoft 365 Expert, Web3 Enthusiast, Jack-of-all-trades and exceptionally gifted Peter Pan. Passionate about digitalisation, collaboration, "boards" (from surf over chess up to monopoly) and Pizza.
Since the announcement by Microsoft of its Project Cortex, at the 2019 Ignite event, there has been a buzz on what to expect from this entire new development. Entirely new? Some argue this is merely an evolution of already existing Microsoft 365 features, to further increase workplace efficiency and productivity.
This is partially true. We all know that especially in enterprise environments, making sure that a tool like Microsoft 365 is put to effective use and does not lead to information overflows and stale content is not a trivial task. Countless information officers have pondered -and continue to ponder- over the best ways of governing an ever-expanding landscape of information repositories and collaborative environments. In these COVID-driven times, the reliance on these environments and tools has only become more critical.
The echo of the nineties🛹
A persistent problem has been the effort to preserve re-usable information, whether for operational reasons like trying to harness built-up know-how, or to derive strategic insights from operational data and information. In the 90’s and with the Digital wave, many initiatives were undertaken to organize the systematic gathering, processing and preservation of this valuable data and information and turn it into a true knowledge management operation.
Few of these initiatives, except perhaps for Big Data, have survived to date. The main reason: the sheer effort and budget needed to install and run this kind of operation, mostly with manual (and thus costly) support. Simply too much effort was spent on searching for information. At the time, search engines where the most advanced tools at our disposal, but they did pose some challenges to effective knowledge management.
This was mostly due to the fact that language-processing technology was still in its infancy, and the accuracy of search results was too low to be of effective use in daily business. The addition of metadata, turning data into information by making its business context more explicit, was of help, but turned into a massive effort in itself, without much automated support.
Project Cortex: Bringing Knowledge and Insights
So what has changed? What is the promise of Microsoft’s Project Cortex, acknowledging that it is explicitly addressing knowledge management? The answer lies in its combination of different information processing technologies, and the integration of these into a new layer of functionality to enhance Microsoft 365 as a platform. This new recipe is to gradually evolve from its current project status into a full-blown Knowledge and Insights product portfolio, with its key ingredients being:
Artificial Intelligence driven content processing
Applying AI principles and features to content processing. As a first installment of Project Cortex, SharePoint Syntex has been released in October 2020, adding AI driven processing capabilities to content hosted in MS SharePoint. With Syntex, you can add content classification and metadata extraction to any SP library, without having too much knowledge of language processing techniques. Hence, an information analyst, not being a data scientist can help set this up, automating your content processing and in doing so, greatly reducing the need for manual metadata management
Knowledge Representation
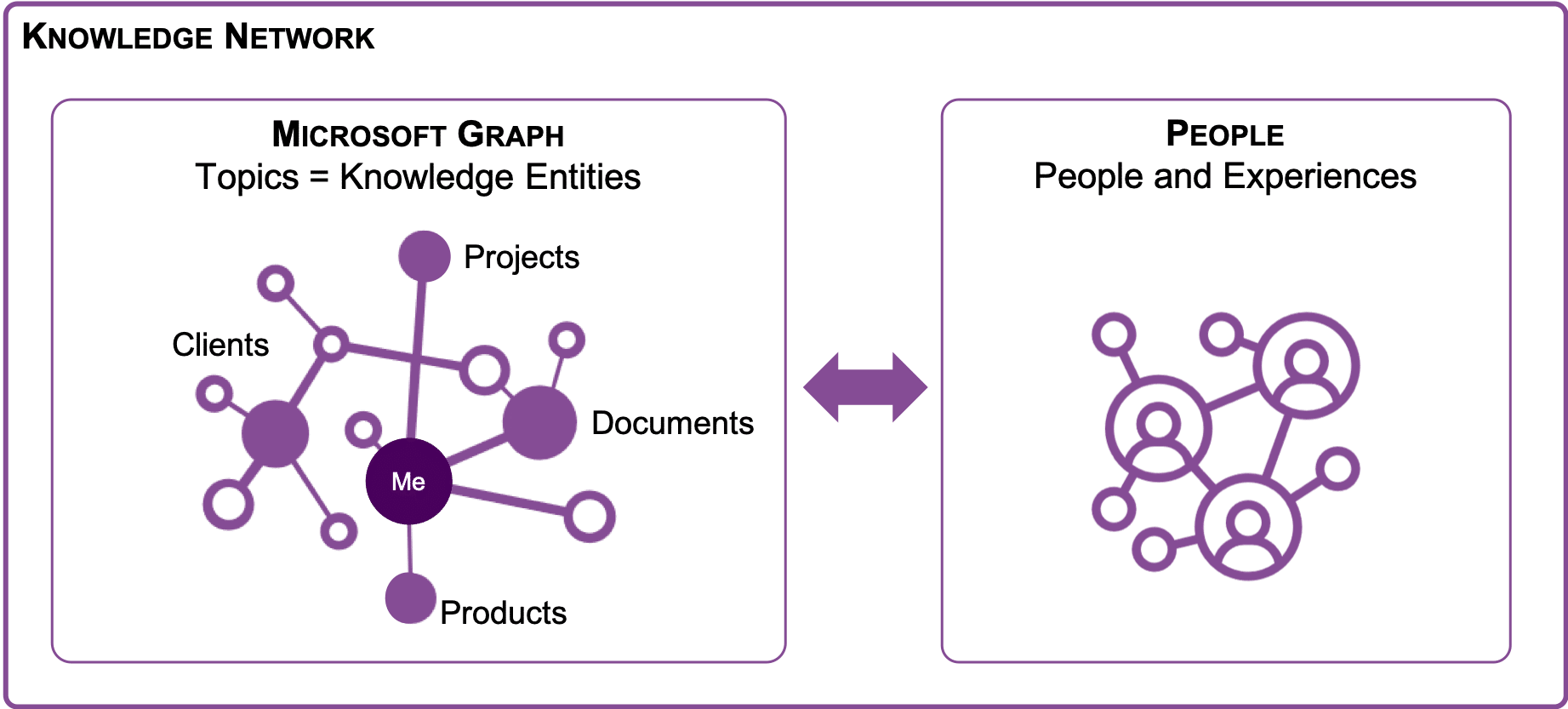
Instead of having to search for information, the next installment of Project Cortex will introduce information being condensed and presented in context through Viva Topics: Topic Cards on any corporate concept, together with Expert Finder profiles will be synthesized and presented from within existing Microsoft 365 components like Office and SharePoint, allowing information workers to almost intuitively enrich and enhance the productivity and quality of their own information-centric tasks
Knowledge Synthesis
Bringing together all of the above, adding workplace analytics and knowledge graphs and integrating the result into Knowledge Centers. When correctly applied and organized around knowledge worker communities, this could well turn into your next generation, knowledge-driven corporate Intranet
With everything in place, the promise of Project Cortex is to enable effective knowledge management on top of your existing Microsoft 365 platform, without having to invest too much in knowledge enablement.
Conclusion
Now as with all Microsoft roadmaps, timing and exact content is subject to change – but the contours so far are clear, and if its perspective is appealing enough, you may already prepare yourself for an effective implementation. Given the potential impact of introducing Project Cortex functionality to the organization, what can we then say up front about any benefits prerequisites and success factors?
First of all, the automation of content processing does away with one of the biggest hurdles to effective information and knowledge management: adding and maintaining (quality) metadata. It is clear to see that with the right (business) context applied, information becomes a lot easier to find, and with Cortex, easier to present accurately at the right time, the right place, for the right persons.
This also suggests, however, a critical prerequisite for successful Project Cortex initiatives: the imperative to have all content that matters available in or at least to the Microsoft 365 platform. As of now, Syntex will only process content that is part of a SharePoint library.
If, for whatever reason, content of importance remains outside of Microsoft 365 (reasons ranging from having it in systems that support compliance driven processes, to the investments already taken on other information repositories and processing platforms), for it to be synthesized into knowledge by Cortex and made available through Microsoft 365 components, it has to be exposed in some way to the Cortex components.
Secondly, to reap the full benefits of automated classification and metadata extraction, it is important to have some form of information standards in place. This may consist of one or more (business domain oriented) information models, having an information structure with classes and security groups, a metadata library, and people appointed to govern these. Most of this would have been implemented already when installing governance for e.g. MS SharePoint, but if not, this is the time to consider it.
Finally, Project Cortex may become the very reason to dust off those knowledge management principles and structures, and serve as the driver to re-organize teams and processes around knowledge, with the aim to serve customers more swiftly and accurately and at a higher quality. If you think about it, implementing this combination of technologies will augment and in the future perhaps replace the robotization efforts undertaken to automate the as-is processes, rather than replacing them with something far more intelligent.




